Picking the Correct XMLHTTP Object

Many OpenInsight applications integrate HTTP calls to extend its capabilities and embrace the power of web services. Whether using the Google Map API to get geolocation information or the UPS APIs to track shipments, applications are doing far more than they ever could before. We were recently approached by ChargeItPro, a leader in payment processing, to help them out. ChargeItPro was going to retire an older web API and replace it one with based on a RESTful architecture. Since ChargeItPro has a number of customers using OpenInsight, they maintain BASIC+ stored procedures and provide them to developers who want to integrate their services. We were asked to convert the logic to work with their new API. This seemed like a fun project, especially since much of the work we are now doing is heavily centered on REST APIs and web services.
On the whole, the conversion to the new API was straight forward. The API follows a very simple flow:
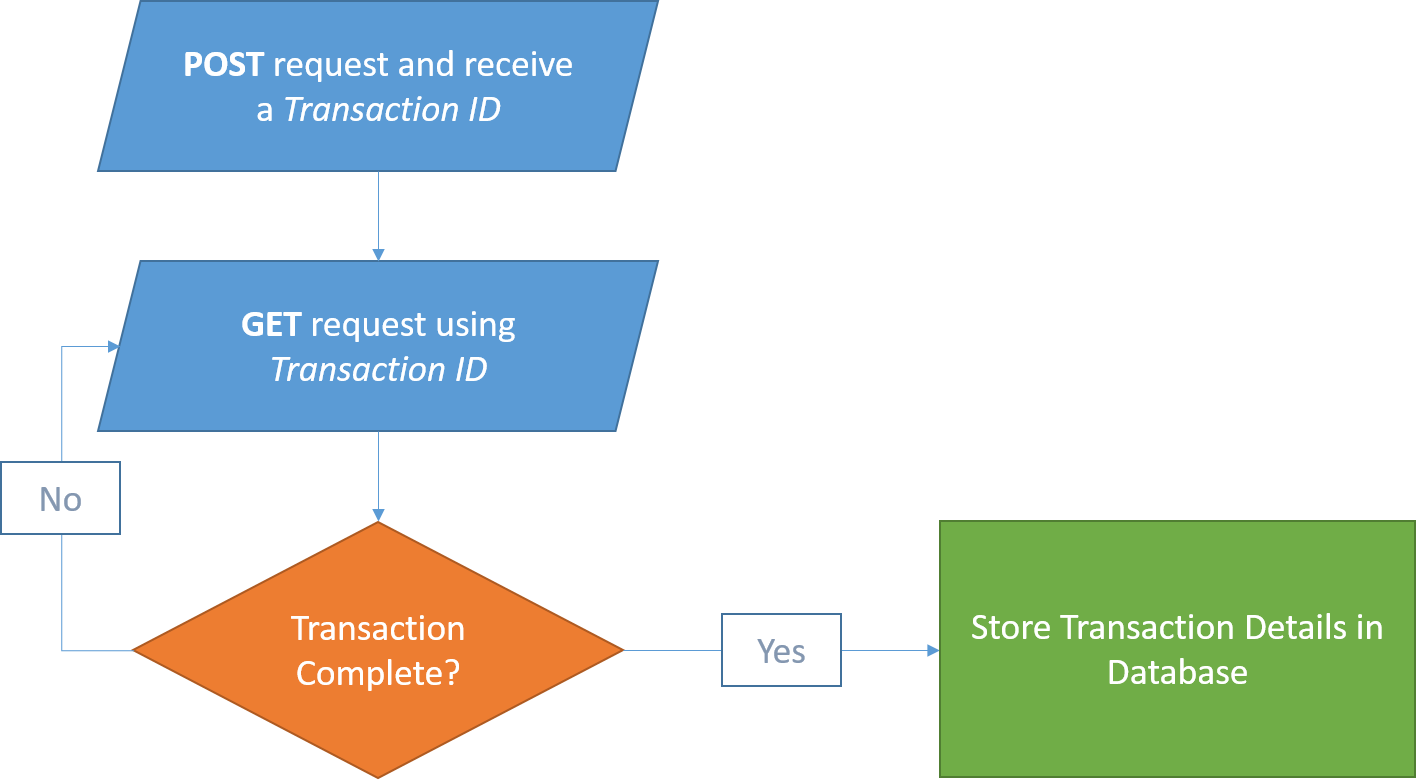
We had the code converted fairly quickly. However, during testing we discovered that there was something that wasn’t working quite right: only the first GET request would actually reach the server. All subsequent attempts would simply return the same response…but it was clear that the server was not receiving any new requests.
After a fair amount of research we discovered that the problem was due to the original XMLHTTP object in the code provided to us:
Msxml2.XMLHTTP.6.0
Before we reveal the nature of the problem, it should be noted that this is a perfectly acceptable XMLHTTP object. Also, in case you didn’t know it, there are two others that can be used:
Msxml2.ServerXMLHTTP.6.0 WinHttp.WinHttpRequest.5.1
Of course, once you start to add in different versions of each object, the list starts to be somewhat lengthy. Nevertheless, the above represent the latest versions, which is what we should be using anyway.
Why are there three different objects? Part of the answer is that WinHttp.WinHttpRequest.5.1 (or WinHTTP for short) has given way to Msxml2.ServerXMLHTTP.6.0 (or ServerXMLHTTP for short). Thus, if we ignore WinHTTP, there are really only two objects. Okay, fine, then why are there two different objects? Good question, especially since it is directly relevant to the problem we were having.
Microsoft’s online documentation states that Msxml2.XMLHTTP.6.0 (or XMLHTTP for short) has a very short description of its purpose:
Provides client-side protocol support for communication with HTTP servers.
This matches our expectations. But what about ServerXMLHTTP? Here’s what its documentation states:
Provides methods and properties that enable you to establish an HTTP connection between files or objects on different Web servers.
The ServerXMLHTTP object offers functionality similar to that of the XMLHTTP object. Unlike XMLHTTP, however, the ServerXMLHTTP object does not rely on the WinInet control for HTTP access to remote XML documents. ServerXMLHTTP uses a new HTTP client stack. Designed for server applications, this server-safe subset of WinInet offers the following advantages:
- Reliability — The HTTP client stack offers longer uptimes. WinInet features that are not critical for server applications, such as URL caching, auto-discovery of proxy servers, HTTP/1.1 chunking, offline support, and support for Gopher and FTP protocols are not included in the new HTTP subset.
- Security — The HTTP client stack does not allow a user-specific state to be shared with another user’s session. ServerXMLHTTP provides support for client certificates.
So…what does all this mean? First, despite using the same properties and methods, they are built around two different technologies: WinInet (XMLHTTP) and WinHTTP (ServerXMLHTTP). It also means that XMLHTTP and ServerXMLHTTP are designed for two different purposes. XMLHTTP is designed for apps (i.e., clients) that need basic browser like functionality from within their code. ServerXMLHTTP is designed for…wait for it…servers! That is to say, when a server is talking to another server, it needs a robust and reliable connection. Clients, on the other hand, are optimized for performance and therefore have quicker timeouts and they can cache results.
It was that last bit of detail that helped to explain why our GET requests were no longer reaching the server. Basically, XMLHTTP did its job and cached our URL request. Armed with this knowledge, we switched the object over to ServerXMLHTTP. Our GET requests were reaching the server as often as we sent them. Problem solved and project completed.
Still, we thought there had to be a way to use the XMLHTTP object and force it to not cache. After doing a bit of searching on this issue, we discovered that this is a common problem that developers from various languages have run into. Fortunately, we found that the If-Modified-Since header helps in this situation, which we implemented like this:
rv = OLECallMethod(Object, "setRequestHeader", "If-Modified-Since", "Sat, 1 Jan 2000 00:00:00 GMT")
This header effectively forces the XMLHTTP object to check in with the server to see if there have been any changes since the date specified in the value. So, both XMLHTTP and ServerXMLHTTP can be used with little or no changes in the code.
We should also report that we had tested the OLE_GetWebPage function and found that it also worked perfectly well. A little deeper digging revealed that this function relies upon the ServerXMLHTTP object, which confirmed our previous conclusions.
Can you use just ‘Msxml2.XMLHTTP’ or ‘Msxml2.ServerXMLHTTP’ (ie, without the version numbers) and the system will use the latest version installed?
Matt,
Alas, no. It isn’t always true that version independent ProgIDs will use the latest version installed. Refer to this link:
http://blogs.msdn.com/b/xmlteam/archive/2006/10/23/using-the-right-version-of-msxml-in-internet-explorer.aspx
The relevant paragraph:
Version Independent ProgIDs – There’s a lot of confusion around the “version-independent” ProgID for MSXML. The version-independent ProgID is always bound to MSXML 3 (a lot of people think it picks up the latest MSXML that is on the box). This means the version independent ProgID and the “3.0” ProgIDs will return the same object.
Dang! – thanks for clearing that up for me 😉
Cheers, M@
Be careful with Msxml2.ServerXMLHTTP though. When a user access the internet using proxy, your client program won’t work. While MSXML2.XMLHTTP will always work as long as your IE can open websites.
Yes, MSXML2.XMLHTTP is version 3.0. Msxml2.XMLHTTP.6.0 is version 6.0. Version 6.0 supports timeouts settings but version 3.0 doesn’t.
One way to avoid caching is simply ad a random number to the end of your url
https://gt4t.net/en/index.php?ran=%random_number%
Thanks for the tip on the proxy issue. I had not come across that information or situation so I’ll keep that in mind. With regard to randomizing the end point to work around the cache, that’s a clever trick but one I would avoid only because there is no way of knowing how a server will respond to an unknown query param. If it were one of my APIs, I would likely return a 4xx error.
It’s not the version 6.0 that supports timeouts but the `ServerXMLHTTP` both 3.0 and 6.0 that has `SetTimeouts` method. Unfortunately `ServerXMLHTTP` is completely unfit for client applications because both `Abort` and `Open` methods spin current thread’s message pump, effectively making your client application reentrant. For server apps pumping messages is not an issue most of the time but for client apps it’s like sprinkling your code with `DoEvents` or similar niceties.
Any advice on using ServerXMLHTTP (or, preferably, OLE_GetWebPage()) to connect with an API that uses digest authentication?
The response headers I get via ServerXMLHTTP come back in OI as a single string with no delimitation, and I can’t parse them cleanly to return the digest-required nonce.
I’d like to use OLE_GetWebPage() to keep the code simple, but I’m not having any luck. I can ‘curl –digest’ via Linux successfully, so I know I can authenticate with the server and get good data, but I can’t seem to get it to work in OI.
OLE_GetWebPage is only designed to return the response body. I’m surprised you are seeing the response headers at all, unless somehow they are a part of the response body and this is why you can’t parse them cleanly. You’ll have to roll-out your own solution using ServerXMLHTTP (which is why we wrote our own HTTPClient_Services module).
Thanks, Don! That explains my issue.
And you are correct — I was getting the headers from ServerXMLHTTP, not OLE_GetWebPage().
Can I ignore certificate errors using XMLHTTP. Many have suggested using setoption( 2,10356) but as I understand it XMLHTTP cannot reference that command and so my client application cannot use XMLHTTP and I’m forced to use ServerXMLHTTP which can reference setoption. I need the client application to handle the warning from performing a POST to a web service that has a self signed certficate.
I don’t know about ignoring the certificate errors, but I can confirm that ServerXMLHTTP is required to use the setOption method.